工业大数据是指工业生产过程中产生的海量、多样、高速的数据集合,其核心在于通过数据采集、处理和分析,优化生产流程、提升设备效率并驱动智能制造。在这个背景下,针对工业大数据的软件开发变得至关重要,它不仅支撑数据的管理与利用,还推动了工业4.0和数字化转型。
工业大数据的特征包括:数据量大(如设备传感器数据、生产日志)、类型多样(结构化与非结构化数据并存)、生成速度快(实时数据流),以及高价值密度(蕴含关键生产洞察)。这些特征对软件开发提出了特殊要求,包括高效的数据存储、实时处理和智能分析能力。
在软件开发方面,工业大数据应用通常涉及多个层次:
- 数据采集层:开发接口和代理程序,用于从工业设备、传感器和系统中收集数据,常见工具如MQTT、OPC UA等协议实现。
- 数据存储层:采用分布式数据库(如Hadoop HDFS、NoSQL数据库)和时序数据库(如InfluxDB)来存储大规模数据,确保可扩展性和可靠性。
- 数据处理层:开发流处理(如Apache Kafka、Flink)和批处理(如Spark)程序,实现实时监控和历史数据挖掘。
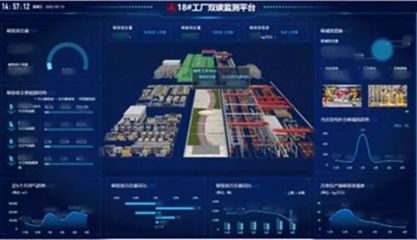
- 分析应用层:构建机器学习模型和可视化平台,例如使用Python或R开发预测性维护算法,或通过Tableau、Grafana展示工业KPI。
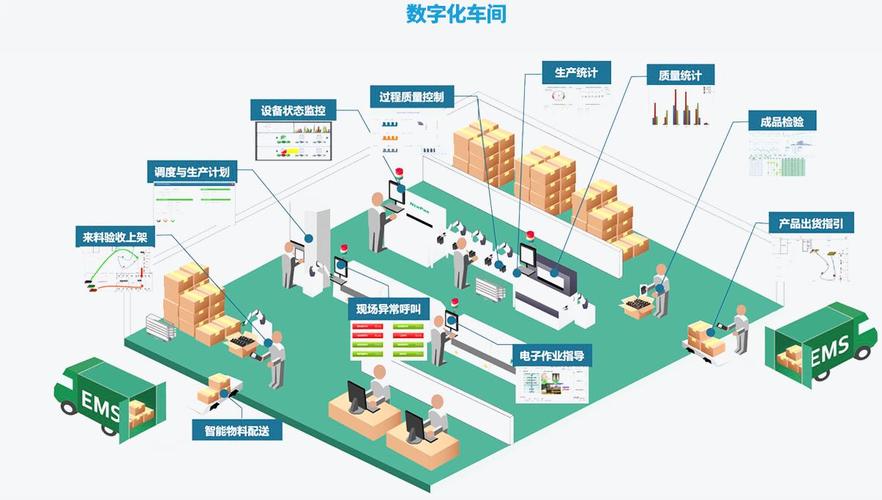
软件开发过程中,需考虑工业环境的特殊性:实时性、安全性和可集成性。例如,在制造业中,软件需与PLC、SCADA系统无缝集成,同时保障数据安全和系统稳定性。常见挑战包括数据异构性、高并发处理和边缘计算部署。
实际应用中,工业大数据软件已用于预测性维护(减少设备停机)、质量控制(实时检测缺陷)和供应链优化。随着AI和IoT的融合,软件开发将更注重自适应性和智能化,推动工业向数字化、网络化发展。
工业大数据的软件开发是连接数据与工业价值的桥梁,通过创新技术栈和敏捷开发方法,企业能释放数据潜力,实现高效、可持续的工业运营。